Follow Us On:

In the modern data landscape, organizations are moving towards cloud-based solutions that allow scalability, flexibility, and cost-efficiency. Two tools that have risen to prominence in this space are Snowflake and DBT. When combined, they form a robust data transformation and modeling solution that simplifies the analytics engineering workflow. In this article, we’ll explore everything you need to know about Snowflake with DBT — from setup to advanced best practices — so you can design, build, and maintain a reliable data pipeline.
Snowflake is a fully managed cloud data warehouse that supports multi-cloud deployment, near-infinite scalability, and separation of compute from storage. DBT (Data Build Tool) is an open-source transformation tool that lets data analysts and engineers write modular SQL to transform raw data into analytics-ready datasets.
The real magic happens when you use Snowflake with DBT because DBT handles transformation logic while Snowflake provides the power to execute transformations at scale.
While Snowflake can handle massive data processing tasks, it is not inherently a modeling tool. That’s where DBT fits in — offering version control, documentation, testing, and modular SQL capabilities. Here’s why Snowflake with DBT is a winning combination:
Separation of concerns: Snowflake focuses on storage and compute, while DBT handles transformations and documentation.
Version-controlled SQL: All transformation code can be stored in Git for collaboration.
Automated documentation: DBT generates data dictionaries and lineage automatically.
Testing and quality checks: Prevents bad data from flowing downstream.
Scalability: Snowflake’s compute clusters ensure DBT transformations run quickly.
When you choose Snowflake with DBT, you enable your data team to work like software engineers — modular, testable, and maintainable.
The architecture for Snowflake with DBT typically follows a layered approach:
Data ingestion layer – Tools like Fivetran, Stitch, or Airbyte load data into Snowflake’s raw schema.
Staging layer – DBT models create clean, structured versions of raw data.
Intermediate models – Transform data into business logic-specific datasets.
Presentation layer – Final tables that feed dashboards and reports.
Documentation and testing – DBT ensures data quality and provides metadata.
Here’s how it works: data is ingested into Snowflake, DBT models run transformations directly in Snowflake using its compute engine, and outputs are written back to Snowflake tables. This is why Snowflake with DBT eliminates the need for separate ETL servers — everything happens inside Snowflake.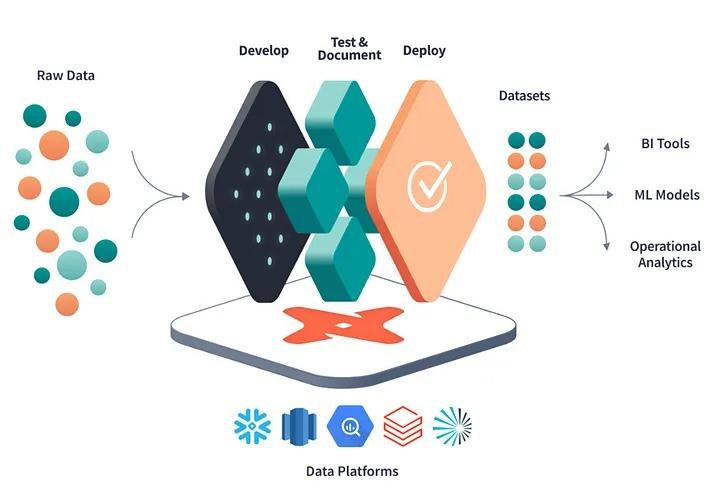
Sign up for Snowflake and create a warehouse, database, and schema.
DBT can be installed using pip:
pip install dbt-snowflake
In your profiles.yml file, configure DBT to connect to Snowflake:
With these steps complete, your environment for Snowflake with DBT is ready for transformation development.
DBT uses SQL and Jinja templating to create models, which are simply .sql files in the models/ folder. A staging model might look like this:
When running dbt run, these models execute inside Snowflake, creating tables or views. In Snowflake with DBT, this modeling approach allows for incremental builds, reducing costs by processing only new data.
Snowflake’s architecture allows for performance tuning using:
Clustering keys – Improve query performance for large datasets.
Materialized views – Speed up repeated transformations.
Result caching – Avoid reprocessing unchanged queries.
When running transformations in Snowflake with DBT, you can specify materialized='incremental' to update only changed records:
This combination minimizes cost and maximizes speed.
Testing ensures your transformations are correct. In Snowflake with DBT, you can write tests in .yml files:
Running dbt test will validate your data directly in Snowflake. DBT also generates HTML documentation and lineage graphs, making Snowflake with DBT a self-documenting pipeline.
While DBT can be run manually, most teams schedule transformations via:
DBT Cloud – SaaS service with scheduling and logging.
Airflow – Orchestration with DAG-based pipelines.
Prefect or Dagster – Modern orchestration tools.
A common production workflow for Snowflake with DBT is:
Trigger data ingestion.
Run DBT transformations in Snowflake.
Test and validate.
Publish data for BI tools.
Adopt modular SQL – Break transformations into smaller, reusable models.
Use incremental models – Save costs and improve run time.
Document every model – Make your data warehouse self-explanatory.
Leverage Snowflake roles – Secure access by user or team.
Monitor costs – Track warehouse credit usage.
Following these ensures Snowflake with DBT stays scalable and maintainable.
Challenge 1: Long-running queries
Solution: Scale Snowflake’s warehouse size temporarily for faster DBT runs.
Challenge 2: Schema drift
Solution: Use DBT sources and tests to detect upstream schema changes.
Challenge 3: Cost overruns
Solution: Adopt incremental materializations in Snowflake with DBT to minimize processing.
E-commerce analytics – Transform order and customer data for better sales insights.
Marketing attribution – Combine ad platform data to track ROI.
Financial reporting – Automate monthly aggregation with DBT models.
IoT analytics – Handle high-velocity sensor data.
In each of these, Snowflake with DBT acts as a unified transformation engine, scaling to billions of rows without infrastructure headaches.
The future looks promising:
AI-powered transformations – Automated model creation from natural language.
Deeper observability – Real-time monitoring of model performance.
Integration with reverse ETL – Sending modeled data back to operational tools.
We can expect Snowflake with DBT to remain a core part of the modern data stack for years to come.
Modern data stacks are built around interoperability — tools must work together seamlessly. Snowflake with DBT integrates easily with ingestion tools like Fivetran, Stitch, and Airbyte, as well as BI platforms such as Looker, Tableau, and Power BI.
The beauty of this pairing is that once data lands in Snowflake, DBT handles all the transformation logic within the warehouse. That means you don’t need to maintain separate ETL servers or deal with the complexity of moving large datasets across environments.
A typical workflow for Snowflake with DBT in the modern data stack looks like this:
Ingestion tool loads raw data into Snowflake.
DBT transformations create clean, analytics-ready datasets.
BI tools connect to Snowflake for visualization.
Data governance tools monitor lineage and quality.
One of the biggest advantages of Snowflake with DBT is its ability to align data analysts, engineers, and business stakeholders. Because DBT models are just SQL files stored in version control systems like GitHub, collaboration feels familiar to developers.
Best practices for team collaboration include:
Using branch-based workflows so multiple analysts can work on different features simultaneously.
Implementing pull request reviews to maintain code quality.
Maintaining a shared DBT documentation site for cross-team understanding.
By centralizing transformation logic in DBT and execution in Snowflake, Snowflake with DBT becomes a single source of truth for analytics engineering.
Most teams run Snowflake with DBT transformations on a fixed schedule — daily or hourly. But advanced scheduling can make pipelines even more efficient:
Event-driven triggers: Run DBT when upstream data arrives in Snowflake.
Conditional logic: Skip transformations if no new data is detected.
Priority tiers: Run business-critical models first, then secondary ones.
Tools like Airflow, Prefect, or DBT Cloud make it easy to implement these advanced scheduling patterns while keeping the Snowflake with DBT pipeline lean and cost-effective.
Many analytics pipelines need to handle changes in reference data over time — for example, tracking a customer’s address history. Snowflake with DBT is well-suited for building SCD Type 2 tables by:
Using DBT macros to detect changes in dimension attributes.
Storing effective start/end dates.
Using incremental models to add new history rows without rewriting old data.
This ensures historical accuracy for reporting while taking advantage of Snowflake’s fast query performance.
When using Snowflake with DBT, it’s important to fully utilize Snowflake’s advanced features:
Streams and Tasks for near-real-time processing.
Time Travel for data recovery and auditing.
Zero-copy cloning for creating test environments quickly.
For example, before testing a new DBT model, you can clone the production schema instantly in Snowflake, run transformations, and validate results — without impacting the live warehouse.
Observability is critical for maintaining trust in your data. For Snowflake with DBT, monitoring should cover:
Model run times to detect performance degradation.
Test results to ensure data quality.
Warehouse credit usage to control costs.
You can integrate DBT run logs with tools like Datadog, New Relic, or Grafana to visualize pipeline health over time.
Although DBT itself isn’t a machine learning tool, Snowflake with DBT can prepare high-quality feature datasets for ML models. By standardizing and transforming data in DBT, data scientists receive clean, consistent tables in Snowflake that are ready for training.
Example workflow:
Use DBT to clean and aggregate transactional data.
Store features in Snowflake tables or views.
Connect Snowflake to ML platforms like DataRobot, SageMaker, or Vertex AI.
This approach keeps data processing centralized and consistent.
Compliance requirements such as GDPR, CCPA, or HIPAA demand strict data governance. With Snowflake with DBT:
Sensitive columns can be masked in Snowflake before DBT processes them.
Data lineage from DBT documentation proves compliance during audits.
Role-based access in Snowflake ensures only authorized transformations occur.
This not only satisfies legal requirements but also builds confidence with customers and regulators.
As data pipelines grow, technical debt can slow progress. Snowflake with DBT helps reduce this by:
Encouraging reusable code via macros.
Automating documentation.
Enforcing testing standards for every model.
By continuously refactoring transformations and removing unused models, you keep the pipeline efficient and maintainable.
The analytics engineering field moves quickly. To stay ahead:
Keep track of Snowflake’s new features, like Snowpark for Python transformations.
Explore DBT’s metrics layer for standardized KPIs.
Integrate with reverse ETL tools to operationalize modeled data.
Organizations that embrace continuous learning will get the most long-term value from Snowflake with DBT.
By pairing the raw power of Snowflake with the transformation capabilities of DBT, you create a modern, scalable, and maintainable data stack. This combination empowers analytics teams to work more like software engineers — with version control, testing, and automation baked into their workflows.
Whether you’re building your first pipeline or optimizing an enterprise data platform, Snowflake with DBT offers the tools you need to succeed in a cloud-first world.